
Issues & Challenges in Urdu OCR
Keywords:
Urdu Recognition Challenges, Urdu OCR, Optical Character Recognition, Character DotsAbstract
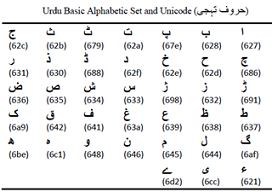
Optical character recognition is a technique that is used to recognized printed and handwritten text into editable text format. There has been a lot of work done through this technology in identifying characters of different languages with variety of scripts. In which Latin scripts with isolated characters (non-cursive) like English are easy to recognize and significant advances have been made in the recognition; whereas, Arabic and its related cursive languages like Urdu have more complicated and intermingled scripts, are not much worked. This paper discusses a detail of various scripts of Urdu language also discuss issues and challenges regarding Urdu OCR. due to its cursive nature which include cursiveness, more characters dots, large set of characters for recognition, more base shape group characters, placement of dots, ambiguity between the characters and ligatures with very slight difference, context sensitive shapes, ligatures, noise, skew and fonts in Urdu OCR. This paper provides a better understanding toward all the possible engendering dilemmas related to Urdu character recognition.
Downloads
Published
How to Cite
Issue
Section
License
University of Sindh Journal of Information and Communication Technology (USJICT) follows an Open Access Policy under Attribution-NonCommercial CC-BY-NC license. Researchers can copy and redistribute the material in any medium or format, for any purpose. Authors can self-archive publisher's version of the accepted article in digital repositories and archives.
Upon acceptance, the author must transfer the copyright of this manuscript to the Journal for publication on paper, on data storage media and online with distribution rights to USJICT, University of sindh, Jamshoro, Pakistan. Kindly download the copyright for below and attach as a supplimentry file during article submission







